MIT课程全解深度学习最前沿-更自动的开发,更快更便宜的好算法
夏乙 发自 凹非寺
量子位 出品 | 公众号 QbitAI
人类公元纪年2019年伊始,深度学习技术也同样处在一个新的“开端”,宜review、宜展望。
MIT正在进行中的深度学习课程就全面描绘了当下的状态。
最近一节课,Lex Fridman老师展现了深度学习各方向的最领先状态,也回顾了过去两年间通往前沿的一步步进展。涉及自然语言处理、深度强化学习、训练和推断的加速等等。
这里的“领先”,只谈想法方向,无关基准跑分。
面对课上展现的大进展,甚至有网友说:
课前喝一杯?机器学习进展如此巨大,简直值得来一两瓶。
视频放出一天多,收获感谢无数。
量子位上完课,结合PPT写了笔记一份,分享给大家。
正式开始前,先来一份小目录。
这节课涉及的重大进展,共12个方面,分别是:
BERT和自然语言处理(NLP)特斯拉Autopilot二代(以上)硬件:规模化神经网络AdaNet:可集成学习的AutoMLAutoAugment:用强化学习做数据增强用合成数据训练深度神经网络用Polygon-RNN++做图像分割自动标注DAWNBench:寻找快速便宜的训练方法BigGAN:最领先的图像合成研究视频到视频合成语义分割AlphaZero和OpenAI Five深度学习框架
我们一个一个细说。
BERT和NLP
2018年是自然语言处理之年。很多圈内人把2012年称为深度学习的ImageNet时刻,因为这一年,AlexNet带来了计算机视觉领域的性能飞跃,激励着人们去探索深度学习在这一领域的更多可能性。
2016年到18年,NLP的发展也类似,特别是BERT的出现。
NLP的发展要从编码器-解码器架构说起。
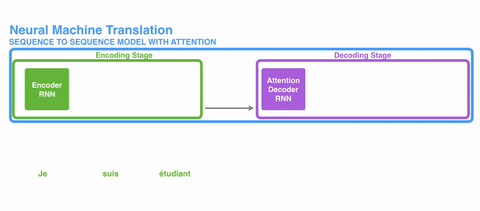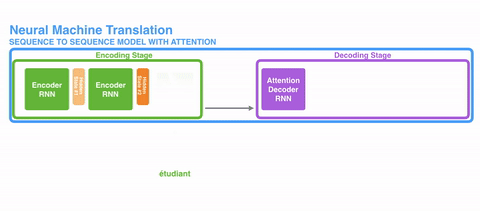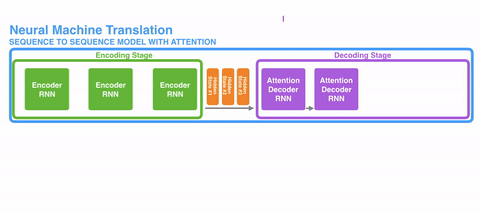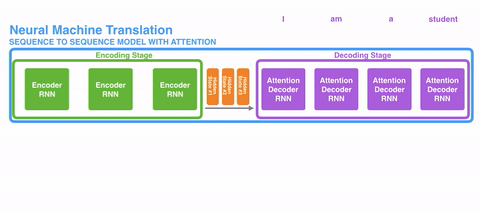
上图展示了一个用于神经机器翻译的序列到序列(seq2seq)模型。RNN编码器负责将输入序列编码成固定大小的向量,也就是整个句子的“表征”,然后把这个表征传递给RNN解码器。
这个架构在机器翻译等领域很管用。
接下来发展出了注意力(Attention)。这种机制,不强迫网络将所有输入信息编码城一个固定长度的向量,在解码过程中还能重新引入输入序列,还能学习输入序列和输出序列中哪一部分互相关联。
比较直观的动态展示是这样的:
再进一步,就发展到了自注意力(Self-Attention),和谷歌“Attention is all you need”论文提出的Transformer架构。
Transformer架构的编码器用自注意力机制为输入序列生成一组表征,解码过程也使用注意力机制。
说完注意力的发展,我们再看一下NLP的一个关键基础:词嵌入。
词嵌入的过程,就是把构成句子的词表示成向量。传统的词嵌入过程用无监督方式将词映射成抽象的表征,一个词的表征参考了它后边的序列。
这是一个语言建模(language modeling)过程。
后来,有了用双向LSTM来做词嵌入的ELMo。
双向LSTM不仅考虑词后边的序列,也考虑它前边的。因此,ELMo词嵌入考虑了上下文,能更好地表征这个词。
接下来出现了OpenAI Transformer。
也就是用先预训练一个Transformer解码器来完成语言建模,然后再训练它完成具体任务。
经过这些进展的积累,2018年出现了BERT,在NLP的各项任务上都带来了性能的明显提升。
它可以用在各种各样的NLP任务上,比如说:
像ELMo一样创建语境化词嵌入;句子分类;句对分类;计算句对的相似度;完成选择题形式的问答任务;给句子打标签;完成普通的问答任务。
量子位之前有回顾2018年深度学习进展、NLP进展的文章,也都详细谈了BERT。
一文看尽2018全年AI技术大突破
不只有BERT!盘点2018年NLP令人激动的10大想法
特斯拉AutoPilot二代硬件
特斯拉的出现毫不意外,量子位之前介绍过,Lex老师是马斯克的小迷弟。
作为神经网络大规模应用的代表,也的确值得一提。
Autopilot二代硬件使用了英伟达的Drive PX 2,还搭载了8个摄像头获取输入数据。
Drive PX 2上运行着Inception v1神经网络,运用摄像头获取的各种分辨率数据进行各种来计算,比如分割可以前进的区域,物体检测等等。
这套系统,已经把神经网络带进了车主们的日常生活中。
AdaNet:可集成学习的AutoML
AutoML是机器学习界的梦想:
将机器学习的一方面或者整个流程自动化,扔一个数据集进去,让系统自动决定所有的参数,从层数、模块、结构到超参数……
谷歌的神经架构搜索,无论从效率还是准确率来看成绩都不错。
2018年,AutoML又有了一些新进展,AdaNet就是其中之一。
它是一个基于Tensorflow的框架,AutoML一样,也是用强化学习方法。不过,AdaNet不仅能搜索神经网络架构,还可以学习集合,将最优的架构组合成一个高质量的模型。
AutoAugment:用强化学习增强数据
从2012年的“ImageNet时刻”到现在,图像识别的新算法层出不穷,成绩一直在提升。
而在计算机视觉里,数据量非常重要,数据增强(data augmentation)也是重要的提升识别率的方法。但是,关于数据增强的研究却不多。
2018年,Google继自动搜索神经架构之后,把数据增强这个步骤也自动化了。
AutoAugment能根据数据集学习这类图像的“不变性”,知道哪些特性是最核心的,然后,神经网络在增强数据时应该让核心特性保持不变。
比如说,它自动增强门牌号数据集的时候,会常用剪切、平移、反转颜色等方法,而在ImageNet这种自然照片数据集上,就不会剪切或者翻转颜色,只会微调颜色、旋转等等。
这个过程和计算机视觉里常用的迁移学习差不多,只不过不是迁移模型权重,而是迁移大型数据集体现出的数据增强策略。
用合成数据训练深度神经网络
很多机构都在研究如何用合成数据来训练神经网络,英伟达是其中的主要势力。
英伟达非常擅长创造接近真实的场景,他们2018年一篇用合成数据训练深度神经网络的论文就充分利用了这一点,合成数据训练的模型,成绩完全不逊于真真实数据。
合成数据还非常灵活多变,比如说汽车、屋子,都能合成出各种各样的数量、类型、颜色、纹理、背景、距离、视角、灯光等等。
关心如何用合成数据训练模型?英伟达的这篇论文值得一读:
Training Deep Networks with Synthetic Data: Bridging the Reality Gap by Domain Randomization
Polygon-RNN++:图像分割自动标注
在训练深度学习模型过程中,数据标注是非常耗时费力的环节。特别如果要标注出语义分割图,就更加麻烦。
Polygon-RNN++是一种自动标注图像的方法,能自动生成一个多边形,来标注出图像里的对象。
它用CNN提取图像特征,然后用RNN解码出多边形的顶点,提出多个候选多边形。然后,一个评估网络从候选中选出最好的。
这也是让深度学习尽可能自动化的一种努力。
Polygon-RNN++的主页上,能找到这一工具的论文、Demo、代码等各种资料
DAWNBench:寻找快速便宜的训练方法
除了让深度学习尽可能自动化之外,还有一个一直受关注的研究方向:让它更易用。也就是快速、便宜。
斯坦福提出的DAWNBench基准,评估的就是模型的速度和成本。它测试各种模型、框架、硬件在ImageNet上达到93%准确率,CIFAR上达到94%准确率的训练、推断速度和成本。
在快速廉价这方面,fast.ai有很好的成绩。他们用租来的亚马逊AWS的云计算资源,18分钟在ImageNet上将图像分类模型训练到了93%的准确率。
他们所用的方法,关键在于在训练过程中逐渐提高学习率、降低momentum,这样就可以用非常高的学习率来训练,还能避免过拟合,减少训练周期。
BigGAN:最领先的图像合成研究
在用GAN合成照片这个方向上,2018年最受人瞩目的成就是DeepMind的BigGAN。
它所用的基本模型没有太大变化,关键在于提升训练规模,增大了模型的容量和训练的批次大小。
BigGAN还提交到ICLR匿名评审时,学界就已经沸腾,因为效果实在是堪称史上最佳。
视频到视频合成
这个领域有一项非常值得关注的研究,那就是英伟达和MIT的“Video-to-Video Synthesis”。
只要一幅动态的语义地图,你就可以获得和真实世界几乎一模一样的视频。

通过一个简单的白描草图,也能生成细节丰富、动作流畅的高清人脸:
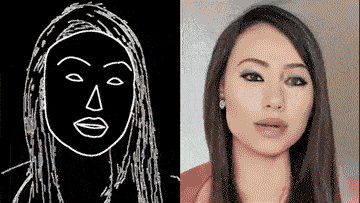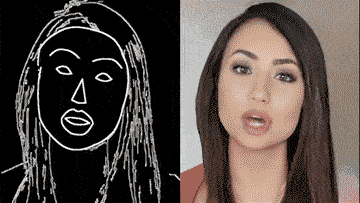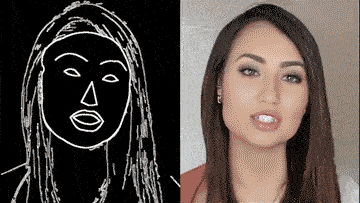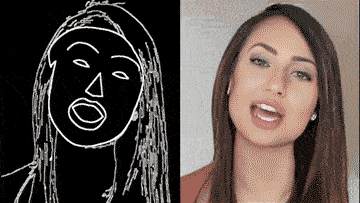
甚至整个身子都能搞定,跳舞毫无压力:

语义分割
视觉感知的问题可以分为三大层级,目前研究最充分的,是分类,也就是图像识别。
然后,是目标检测:在一幅图像里,框出物体,识别出它是什么。
关于目标检测的研究非常多:
其中不少工作很exciting,但Lex老师认为哪一个都称不上“突破”。
而语义分割,是视觉感知问题的最高层级。
现在,这一领域的最好成绩属于DeepLab v3+。
关于语义分割的重要研究,可以说从2014年的FCN开始,经历了2015年的SegNet、Dilated Convolutions的发展,2016年出现了DeepLab v1、v2版本。
DeepLab系列用ResNet来提取图像特征,增加了全连接条件随机场(CRF)作为后续处理步骤,能捕捉图像中的局部和长距离依赖,优化预测图,还引入了空洞卷积。
在前两版的基础上,DeepLab v3又增加了多尺度分割物体的能力。
AlphaZero和OpenAI Five
用强化学习打游戏这件事,2018年也有明显进步。
这个领域最初的尝试,是DeepMind用强化学习算法玩了一遍雅达利的小游戏,推出了DQN。
随后,就是围棋AI AlphaGo广为人知的一系列发展:
从AlphaGo到AlphaZero的过程,也是一个越来越节约人工、机器自主性越来越高的过程。
AlphaZero掌握围棋、国际象棋、日本将棋三大棋类,但都是完美信息、规则清晰游戏。而OpenAI把目光投向了更混乱的试验场:Dota 2。
对于强化学习算法来说,Dota 2更接近真实世界的情况,它需要解决团队协作、长时间协调、隐藏信息等问题。
OpenAI在Dota 2上取得的进展如下:
2017年,他们的算法在1v1比赛中击败顶尖选手Dendi;2018年,5v5的AI队伍OpenAI Five在Dota比赛TI上对战顶尖职业选手,输了两局。
未来仍需努力。
深度学习框架
回顾整个2018年,深度学习框架排名是这样的:
框架的格局会往什么方向发展?要看这样几个用户关心的因素:
学习曲线开发速度社区的规模和热情用这一框架实现的论文数量长期发展和稳定的可能性工具生态
2019展望
要展望2019,我们应该好好思考Hinton谈过的两个观点:
关于反向传播:“我的观点是把它完全抛弃,从头再来。”
“未来取决于我说什么都深切好奇的那些研究生们。”
最后,附完整PPT:
https://www.dropbox.com/s/v3rq3895r05xick/deep_learning_state_of_the_art.pdf?dl=0
量子位(公众号QbitAI)还在网盘传了一份PPT,在公众号对话界面回复“最前沿”可得。
— 完—
相关文章:
- [亚博体育]当爹了就是不一样!范乔丹儿子出生后,3大数据飙升速度达300%!
- [亚博体育]追梦西决打得很棒 但库里更超卓 对球队更主要
- [亚博体育]范乔丹天坑数据上微博热搜,求求纳斯上米克斯或者林书豪吧
- [亚博体育]亚博罗本和里贝里在10年间塑造了德甲和拜仁
- [亚博体育]滑铁卢式下滑!利拉德三轮系列赛数据对照
- [亚博体育]亚博体育斯特林可能在欧国联半决赛中担负英格兰队长
- [亚博体育]亚博体育疯狂德甲收官战!药厂进欧冠,狼堡8球年夜胜奥堡霍村崩盘
- [亚博体育]亚博体育但愿球队高层听取波帅定见,知足他提出的要求
- [亚博体育]亚博体育我收到良多约请,除德甲还其他两个联赛
- [亚博体育]亚博体育德赫亚是不是留队,或取决在曼联门将锻练的续约环境
相关推荐:
- [中超]恒大U15夺冠!中非混血前锋爆发,进11球当选MVP,有望接班张玉宁
- [CBA]CBA俱乐部杯-詹姆斯32+15 天津胜广东
- [意甲]阿德利:只要我表现出色紫百合就会从米兰买断我 紫百合很信任我
- [西甲]已和皇马达成协议?阿方索·戴维斯经纪人怒斥转会传闻
- [英超]曝曼联试水奥斯梅恩转会,明夏或7000万引进!阿莫林首选并非嫡系
- [欧冠]马里诺夫给力、米哈神勇!泽仁体育爆冷击败费内巴切!
- [NBA]湖人拔刺4连胜 浓眉40+12詹皇三双文班28+14
- [中超]连续4场被弃,泰山队归化成鸡肋 等待身份转换 费南多+帕托不续约
- [CBA]前瞻:全华班辽宁阻止3连败?新疆青岛关键战
- [意甲]卡佩罗:米兰VS尤文谁输就可能退出意甲争冠,米兰必须改善防守
网友评论: